
Summary -
In this topic, we described about the Reducer with detailed example.
In MapReduce algorithm, reducers are the second phase of processing. Reducers is used for final summation and aggregation. After the map phase is over, all the intermediate values for the intermediate keys are combined into a list.
Reducer takes the intermediate (key, value pairs) output stored in local disk from the mapper as input. Reducer task, which takes the output from a mapper as an input and combines those data tuples into a smaller set of tuples. There may be single or multiple reducers.
Several reducers can run in parallel since they are independent of each other. All the values associated with an intermediate key are guaranteed to go to the same reducer. The intermediate key and their value lists are passed to the reducer in sorted key order.
The reducer outputs zero or more final key/value pairs and these are written to HDFS.
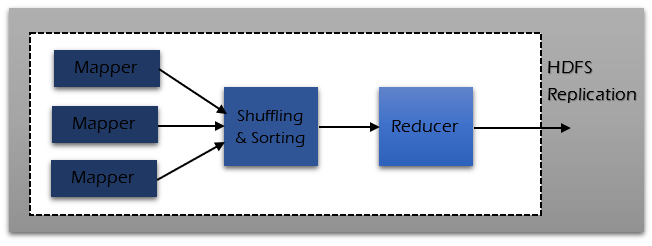
Reducer has 3 phases -
- Shuffle - Output from the mapper is shuffled from all the mappers.
- Sort - Sorting is done in parallel with shuffle phase where the input from different mappers is sorted.
- Reduce - Reducer task aggerates the key value pair and gives the required output based on the business logic implemented. The output of reducer is written on HDFS and is not sorted.
With the help of Job.setNumreduceTasks(int) the user set the number of reducers for the job. The number of reducers are calculated lke below -
Number of reducers = <0.95 or 1.75> * <no. of nodes> * <no. of the maximum container per node>.
With 0.95, all reducers immediately start transferring map outputs as the maps finish. With 1.75, the first round of reducers is finished by the faster nodes and second round of reducers is launched doing a much better job of load balancing.