
Hadoop Big Data Overview
How the data is increasing?
In recent years, communication among people has increased significantly due to modern technologies and devices. Every interaction by an individual on the internet generates data in the background. This data is growing rapidly as internet traffic continues to rise daily.
Let's examine some statistics that illustrate how global internet traffic has drastically increased over the years.
- In 1992, global internet traffic was 0.0017 GB/sec.
- By 1997, it had risen to 0.028 GB/sec.
- In 2002, the traffic surged to 100 GB/sec.
- By 2013, internet traffic reached 28,875 GB/sec.
Forecasts suggest that by 2025, global data traffic is expected to reach approximately 1 petabit per second (1,000 terabits per second).
What is Big Data?
Big data refers to data that exceed the processing capacity of conventional techniques and database systems. This type of data typically includes volumes that are too large for commonly used software tools to manage or process effectively.
The data is too big and grows too fast. The data is large, too big, creates too fast and don't have a proper structure.
The data comes from everywhere like,
- Sensors to gather climate information
- Satellite images
- Social media posts
- Digital pictures
- Videos
- Purchase transaction records
- Banking transactions
- Content of Webpages
- Cell phone GPS signals
- Web server logs
- Financial market data and so on…
Big Data Challenges -
The Big data challenges include
- Capture the data
- Processing the data
- Storing data
- Searching data
- Analyzing data
- Sharing data
- Transfering data
- Presenting data
Big Data 3vs -
Three Vs are commonly used to characterize various aspects of big data -
- Volume
- Velocity
- Variety
The three Vs provide a useful framework for understanding the nature of data. There are software platforms available that can be leveraged, and it's likely that the data can be accessed at various stages concerning each of the Vs.
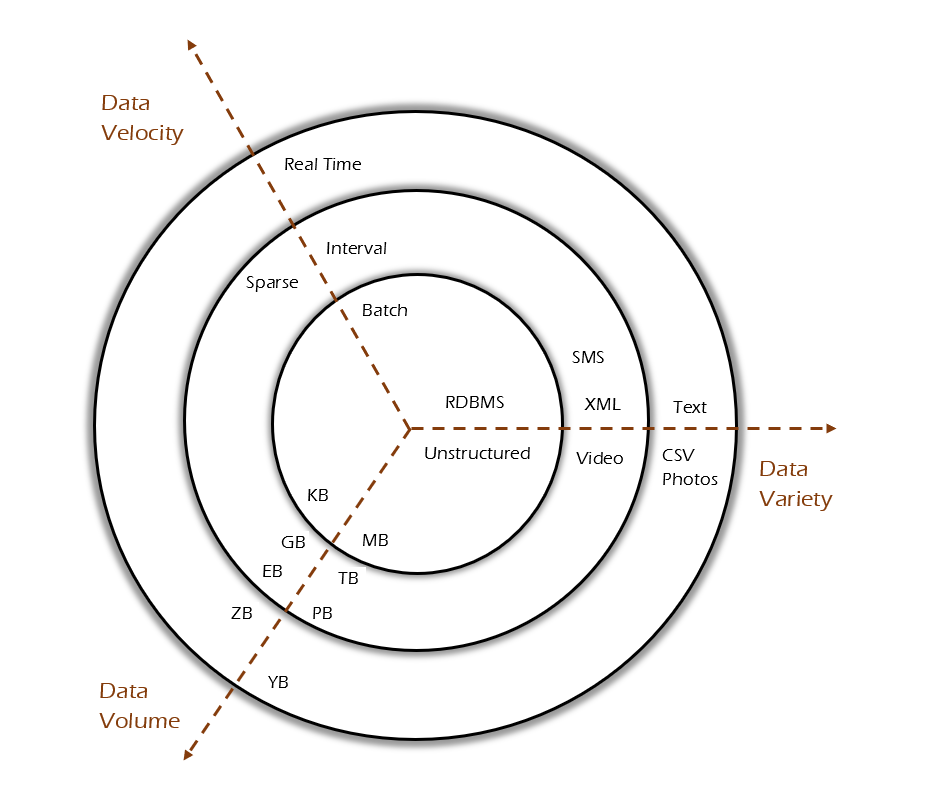
Volume -
Volume describes the amount of data generated from different sources. Volume always talks about size of the Data. The process is a batch operation and it suits for analytical or non-interactive computing tasks.
Example:
The amount of data is increasing day by day. This data is generated by individuals, companies, social networking sites, and more.
For example, consider a website. On a website, the publisher creates content that can be read by both registered and unregistered users, who can then generate additional data through their comments. The generation of data depends on the number of users visiting a particular site. As the number of users increases, the amount of data generated also tends to rise. If the volume of data grows significantly, it is classified as Big Data.
Velocity -
Velocity refers to the frequency at which data is generated, captured, and shared. It's not just about how fast data comes in; it also means you can stream quick-moving data into bulk storage for later use in batch processing.
In industry terminology, this fast-moving data is often referred to as "streaming data" or "complex event processing." There are two main reasons to consider streaming processing: the first is when the input data is generated too quickly to be stored in its entirety. The second reason is when an application requires an immediate response to incoming data.
Example:
In the past, data processing primarily relied on batch processing, with update intervals that could last for hours. For example, before 2003 in media, the news update window gap was very high and the news updates showing for specific day are the news from the day before specific day. Today, however, social media platforms like Facebook and news channels provide live updates. As a result, many people often lose interest in news that is even just an hour old.
The data movement now days are almost real time and the update window got reduced to fraction of seconds. The velocity of real time data updates has been increased to very high and this high velocity data represents the Big Data.
Variety -
Variety refers to the different types of data. Data can be classified as either structured or unstructured, with examples including text, sensor data, audio, and video.
A common use of big data processing is to convert unstructured data into organized information for analysis. It's important to note that during the process of transferring data from the source to the processing application, there may be a loss of information.
Example:
If the data is in a consistent format, then the processing can be simple and easy. Data can be stored in various formats, such as databases, Excel files, documents, and plain text. However, there are times when the data may be in a format that is difficult to understand.
Additionally, data can exist in unstructured formats, like audio and video. The main challenge lies in organizing this data and processing it in a way that makes it meaningful for use. The diverse types of data are what characterize Big Data.
Big Data Uses -
Big data is incredibly useful and plays a crucial role in creating statistics or reports from data collected from various sources. A common use of big data processing is to take unstructured data and extract meaningful, organized insights for analysis.
Below are the examples of some uses -
- Real-time transport information by collecting the data from various sensors or GPS data from various sources.
- Healthcare trends information by collecting the data from various places or locations about diseases.
- Economic Development based on the reports generated from existing trends and predicts current trends.
- Similarly Social networking reports, Retail information reports, crime reports etc,.
Big Data Types -
The big data can be separated as three types -
- Structured data. Ex: Data in DB tables or Relational data.
- Semi Structured data. Ex: XML.
- Unstructured data. Ex: Videos, images, text etc.
We have RDBMs already in hand to process structured Databases and tables which are in the form of rows and columns. But now a days, we are getting the data in the form of videos, images and text etc. and known as semi structured or unstructured data.
This data can't be processed by RDBMs and need an alternative way to store and process the unstructured or semi structured data. The solution for the Big Data problem is Hadoop. Hadoop is entirely different from traditional systems processing and can overcome all the above problems to process the data.