
Hadoop HDFS Architecture
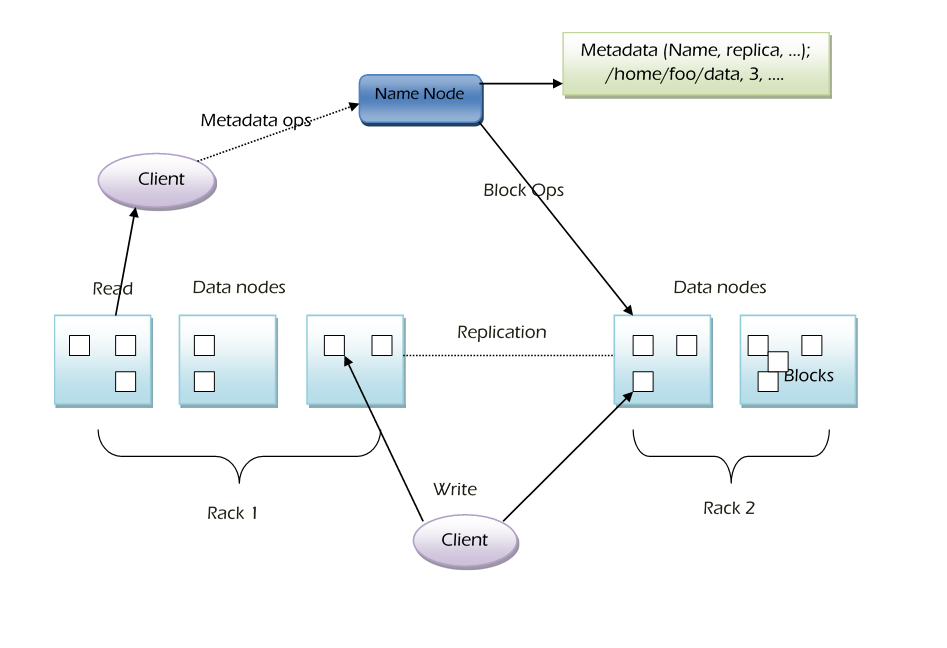
Hadoop utilizes a Master-Slave architecture consisting primarily of two daemons. A daemon is a background service that operates within Hadoop. The major two daemons are -
- Master Daemons
- Slave Daemons
The two daemons are organized into subnodes, as shown below -
- Master Daemons
- Name Node
- Secondary Name Node
- Job Tracker
- Slave Daemons
- Data Node
- Task Tracker
Let’s discuss on each node in detail.
Name Node -
The Name Node is a key component of HDFS architecture in Hadoop, responsible for maintaining the directory tree of files across the cluster. It does not store actual file data; instead, client applications interact with it to manage files — adding, copying, moving, deleting, or locating them. The Name Node manages the metadata of the file system and poses a single point of failure; if it goes down, the entire file system is inaccessible.
The Name Node will update two important permanent files with the entire file information -
- Fsname space image
- Edit log
Secondary Name Node -
The Secondary NameNode is now deprecated and plays a role in periodically checking the namespace. It helps maintain the size of the HDFS modifications log within manageable limits at the NameNode. The Secondary NameNode has been replaced by the Checkpoint Node.
When the primary node is down, the Secondary Name Node takes over. The Name Node keeps track of changes to the file system by logging them in a file called the edits log. When the Name Node starts up, it reads the current state of the HDFS from an image file known as fsimage and then applies the changes recorded in the edits log. After this process, the Name Node writes the updated HDFS state back to the fsimage file and begins normal operations with a new, empty edits file.
The checkpoint process on the secondary NameNode is initiated by two configuration parameters -
- ·fs.checkpoint.period - This parameter is set to a default of 1 hour and specifies the maximum time allowed between two consecutive checkpoints.
- ·fs.checkpoint.size - This parameter is set to a default of 64 MB and defines the size of the edits log file that triggers an urgent checkpoint, even if the maximum checkpoint delay has not been reached.
Task Tracker -
A Task Tracker is a node within a cluster that accepts tasks such as Map, Reduce, and Shuffle operations from a Job Tracker. The Task Tracker is responsible for instantiating and monitoring individual map and reduce tasks. It is also known as a software daemon in the Hadoop architecture.
Each Task Tracker is configured with a set of slots, which indicate the number of tasks it can handle simultaneously. The primary function of the Task Tracker is to execute the tasks assigned by the Job Tracker in the form of MapReduce jobs. Generally, Task Trackers operate on data nodes within the cluster.
Job Tracker -
The Job Tracker is a part of Hadoop that manages tasks in the cluster. It schedules and reschedules MapReduce jobs. The Job Tracker receives updates from the Task Tracker.
The Job Tracker works with the Name Node. Client applications submit jobs to the Job Tracker. The Job Tracker checks with the Name Node to find out where the data is stored. It then identifies Task Tracker nodes that have available slots, preferably close to the data. Finally, the Job Tracker assigns the tasks to the selected Task Tracker nodes.
If a Task Tracker does not send heartbeat signals on time, it will inform the Job Tracker that the task has failed. The Job Tracker will decide what to do next: it might send the job to a different location, mark the specific record to avoid in the future, or even list the Task Tracker as unreliable.
Once the work is completed, the Job Tracker updates its status. It is important to note that the Job Tracker represents a potential point of failure for the Hadoop MapReduce service. If it goes down, all running jobs will be halted.
Data Node -
A Data Node stores data in the Hadoop File System and is the place to hold the data. A functional file system has more than one Data Node with data distributed across the Data Nodes. Actual data in data nodes only in the form of HDFS blocks and by default, each block size is 64MB.
In the beginning, Data Node connects to the Name Node and establishes the service. Then Data Node responds to requests from the Name Node for file system operations. Data Nodes are store and retrieve blocks, reporting name nodes.
Client applications can talk directly to a Data Node by using the location of the data provided by Name Node. Task Tracker instances can indeed should be deployed on the same servers that host Data Node instance exists. A client accesses the file system on behalf of the user by communicating with data nodes.
There is usually no need to use RAID storage for Data Node data. Data is designed to be replicated across multiple servers, rather than multiple disks on the same server.
An ideal configuration is for a server to have a Data Node, a Task Tracker, and then physical disks one Task Tracker slot per CPU. This will allow every Task Tracker 100% of a CPU and separate disks to read and write data.