
Apache Flume Architecture
The image below represents the basic architecture of Flume. As shown, data generators (such as Facebook and Twitter) produce data that is collected by individual Flume agents operating on these platforms. Subsequently, a data collector, which is also an agent, gathers the data from the various agents, aggregates it, and then pushes it into a centralized storage system, such as HDFS or HBase.
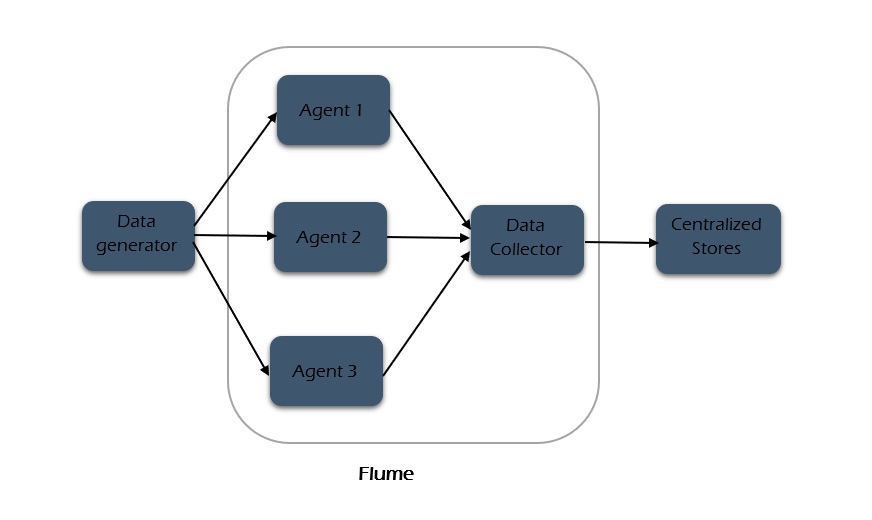
Let’s discuss in detail about each entity in the architecture.
Event -
A Flume event is the smallest piece of data that Flume moves around. It has a payload—typically a byte array containing your actual data—and optional headers that add extra context (like timestamps or tags)
For example - Think of it as a packaged shipping container: the payload is what you’re sending, and headers are the labels that help you route or interpret it.
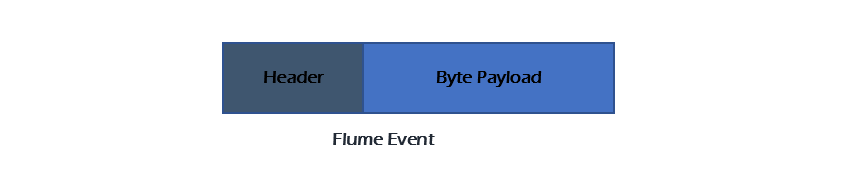
This simple design—payload + headers—keeps things flexible and easy to manage no matter what type of data you’re dealing with.
Flume Agent -
A Flume agent is the working unit in Flume — it is an independent Java process (JVM) running on a machine. You can have multiple agents in your system, each handling different parts of the pipeline or scaling across servers.
For example - Agents run like friendly couriers: receive events, hold them safely, and then pass them on to the next stop in the journey.
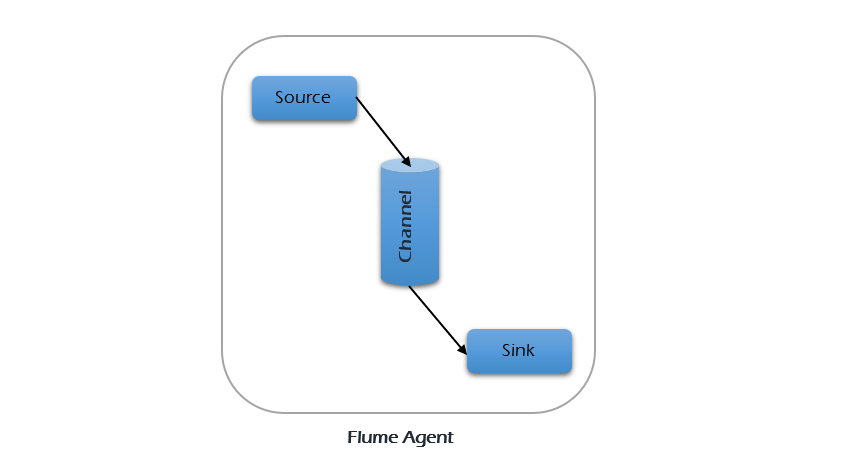
A Flume Agent consists of three main components: source, channel, and sink.
Source -
A source is the component of an agent that receives data from data generators and transfers it to one or more channels in the form of Flume events. Apache Flume supports various types of sources, and each source is designed to receive events from a specific data generator.
Examples include the Avro source, Thrift source, and Twitter 1% source.
Channel -
A channel is a temporary holding area (like a buffer) inside an agent. It stores events received from the source until the sink is ready to process them, making sure nothing gets lost.
Channels are fully transactional and can work with multiple sources and sinks simultaneously. Examples include the JDBC channel, file system channel, and memory channel.
Sink -
A sink is where events end up—they get taken from a channel and delivered to the final destination. That destination could be HDFS, HBase, another Flume agent, or even some external system. Sinks pull events from the channel, send them out, and confirm the event is processed before marking it complete.
Examples include the HDFS sink and Avro sink; but you can plug in more depending on your architecture
Additional Components of Flume Agent -
Flume agents include more than just source-channel-sink—they come with extras that help control the flow and transform data. These include interceptors, channel selectors, and sink processors — which you can use to filter, route, or balance your data. They’re like extra toolkits that give your agent superpowers: inspecting, duplicating, or re-routing events on the fly.
Interceptors -
Interceptors sit between the source and channel and let you inspect or tweak events before they get buffered. Use them to add extra headers, drop events that don’t match certain criteria, or transform payloads. Want to tag incoming logs with a regional code, or filter out debug messages? An interceptor does that.
Channel Selectors -
When your agent has multiple channels, channel selectors help decide which channel gets a given event. There are two main types:
- Default (replicating): sends the same event to all channels, like broadcasting.
- Multiplexing: picks a specific channel based on header values (like a mail sorter). These selectors help you build complex pipelines easily—one source branching out into multiple funnels.
Sink Processors -
Sink processors operate after the channel—they manage which sink gets pulled and in what order. They support load balancing (evenly distributing events across sinks) or failover (automatic rerouting to a healthy sink).
Imagine having two HDFS sinks; the processor ensures events go evenly to both or switch if one fails. These make your data pipeline robust and efficient—no manual intervention required.