
Apache Flume Data Flow
Flume is a framework used to transport log data into HDFS (Hadoop Distributed File System). Typically, log events and data are generated by log servers that have Flume agents running on them. These agents receive data from the data generators.
The data collected by these agents is then sent to an intermediate node known as a Collector. Like agents, there can be multiple collectors in a Flume setup.
Ultimately, the data from all these collectors is aggregated and pushed to a centralized storage system, such as HBase or HDFS. The following diagram illustrates the data flow within Flume.
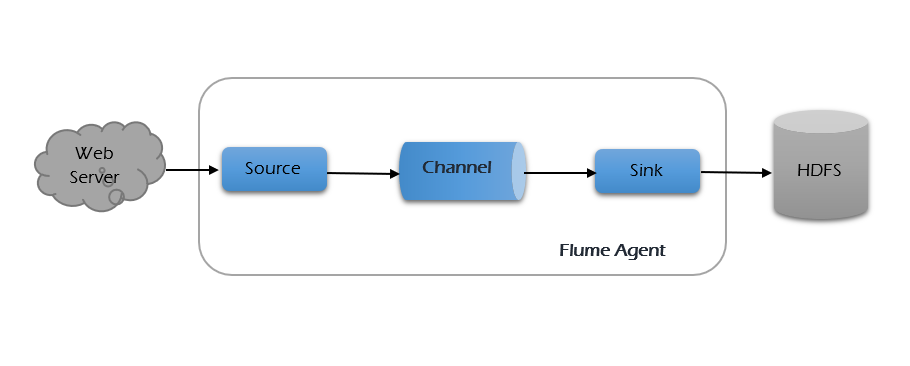
Multi-hop flow -
A multi-hop flow happens when an event passes through more than one Flume agent before landing in its final destination. Think of it like a relay race: your website’s log hits Agent A, which forwards it to Agent B (a collector), and only then does it get saved into HDFS. This setup helps when your web servers can't connect directly to Hadoop—you can use an intermediate agent as a bridge.
The below diagram shows the multi-hop flow.
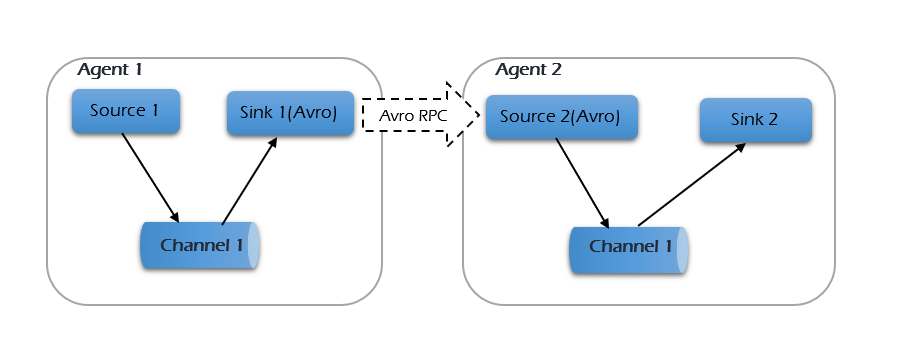
Fan-in flow -
The data transferred from many sources to one channel is known as fan-in flow. A fan-in flow is the opposite—multiple sources send data to one channel. Imagine logs from your web server, app server, and database all feeding into a single Channel A on Collector Agent. That central channel then backs up everything and hands it off to HDFS or another sink.
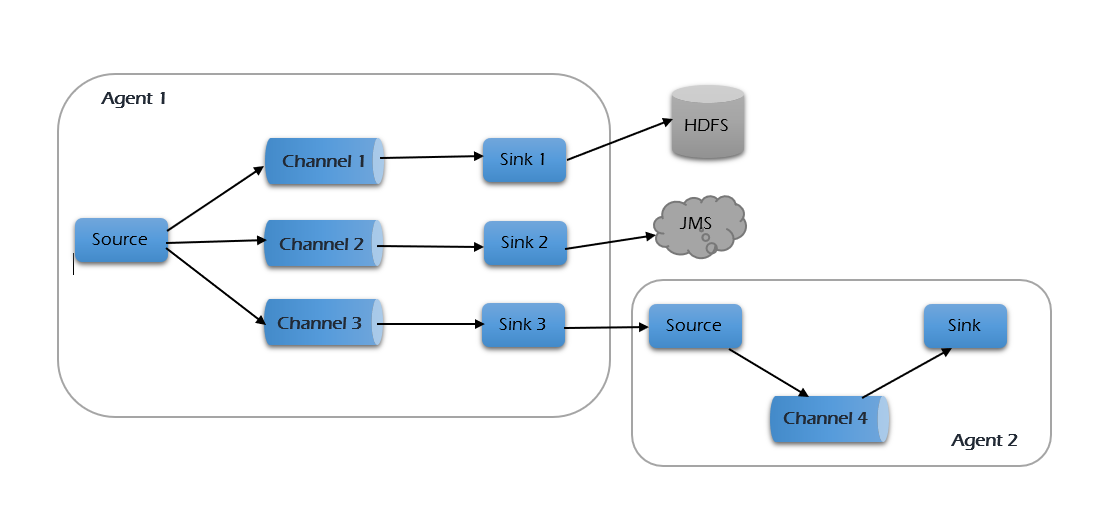
Fan-out -
Fan-out flow is when one source sends its data to multiple channels simultaneously. There are two flavors:
- Replicating: sends every event to all configured channels—like copying a log to both HDFS and HBase.
- Multiplexing: uses event headers to decide the destination—e.g., type=error goes to ErrorChannel, while type=info goes to InfoChannel.
Failure Handling -
Flume uses a built-in transaction system to make sure no data gets lost when something fails. Here’s how it works:
- Sender sends an event to the receiver (channel or sink).
- Receiver stores the event and commits its own transaction, then sends an acknowledgment back.
- Sender waits for that acknowledgment—only then does it commit its own transaction.
If something goes wrong at any step, the event isn’t lost—it stays in the system until it can successfully go through again.