
MapReduce Architecture
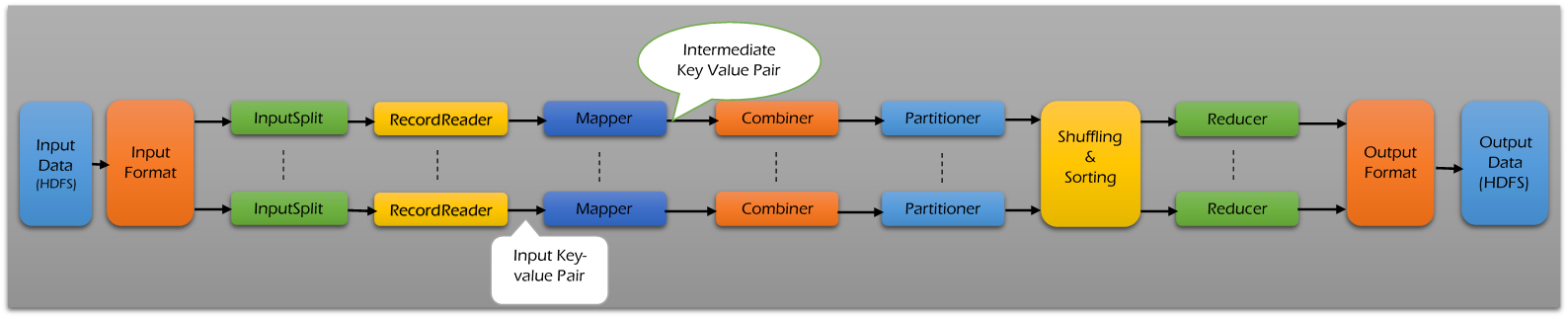
MapReduce is a programming model and expectation is parallel processing in Hadoop. MapReduce makes easy to distribute tasks across nodes and performs Sort or Merge based on distributed computing.
The underlying system takes care of partitioning input data, scheduling the programs execution across several machines, handling machine failures and managing inter-machine communication.
Input will be divided into multiple chunks/blocks. Each and every chunk/block of data will be processed in different nodes. MapReduce architecture contains the below phases -
- Input Files
- InputFormat
- InputSplit
- RecordReader
- Mapper
- Combiner
- Partitioner
- Shuffling and Sorting
- Reducer
- RecordWriter
- OutputFormat
Input Files -
In general, the input data to process using MapReduce task is stored in input files. These input files typically reside in HDFS (Hadoop Distributed File System). The format of these files is random where other formats like binary or log files can also be used.
InputFormat -
InputFormat describes the input-specification for a Map-Reduce job. InputFormat defines how the input files are to split and read. InputFormat selects the files or other objects used for input.
InputFormat creates InputSplit from the selected input files. InputFormat split the input into logical InputSplits based on the total size, in bytes of the input files.
InputSplit -
InputSplit is created by InputFormat. InputSplit logically represents the data to be processed by an individual Mapper. One map task is created to process one InputSplit.
The number of map tasks normally equals to the number of InputSplits. The InputSplit is divided into input records and each record is processed by the specific mapper assigned to process the InputSplit. InputSplit presents a byte-oriented view on the input.
RecordReader -
RecordReader communicates with the InputSplit in Hadoop MapReduce. RecordReader reads <key, value> pairs from an InputSplit. RecordReader converts the byte-oriented view of the input from the InputSplit.
RecordReader provides a record-oriented view of the input data for mapper and reducer tasks processing. RecordReader converts the data into key-value pairs suitable for reading by the mapper.
RecordReader communicates with the InputSplit until the file reading is not completed. Once the file reading completed, these key-value pairs are sent to the mapper for further processing.
Mapper -
Mapper processes each input record and generates new key-value pair. Mapper generated key-value pair is completely different from the input key-value pair. The mapper output is called as intermediate output.
The mapper output is not written to local disk because of it creates unnecessary copies. Mappers output is passed to the combiner for further process.
Map takes a set of data and converts it into another set of data, where individual elements are broken down into key pairs. The Mapper reads the data in the form of key/value pairs and outputs zero or more key/value pairs.
Combiner -
Combiner acts as a mini reducer in MapReduce framework. This is an optional class provided in MapReduce driver class. Combiner process the output of map tasks and sends it to the Reducer.
For every mapper, there will be one Combiner. Combiners are treated as local reducers. Hadoop does not provide any guarantee on combiner’s execution.
Hadoop may not call combiner function if it is not required. Hadoop may call one or many times for a map output based on the requirement.
Partitioner -
Partitioner allows distributing how outputs from the map stage are send to the reducers. Partitioner controls the keys partition of the intermediate map-outputs. The key or a subset of the key is used to derive the partition by a hash function.
The total number of partitions is almost same as the number of reduce tasks for the job. Partitioner runs on the same machine where the mapper had completed its execution by consuming the mapper output. Entire mapper output sent to partitioner.
Partitioner forms number of reduce task groups from the mapper output. By default, Hadoop framework is hash based partitioner. The Hash partitioner partitions the key space by using the hash code.
Shuffling and Sorting -
The output of the partitioner is Shuffled to the reduce node. The shuffling is the physical movement of the data over the network. Once the mappers finished their process, the output produced are shuffled on reducer nodes.
The mapper output is called as intermediate output and it is merged and then sorted. The sorted output is provided as a input to the reducer phase.
Reducer -
After the map phase is over, all the intermediate values for the intermediate keys are combined into a list. Reducer task, which takes the output from a mapper as an input and combines those data tuples into a smaller set of tuples. There may be single reducer, multiple reducers.
All the values associated with an intermediate key are guaranteed to go to the same reducer. The intermediate key and their value lists are passed to the reducer in sorted key order. The reducer outputs zero or more final key/value pairs and these are written to HDFS.
RecordWriter & OutputFormat -
RecordWriter writes these output key-value pair from the Reducer phase to the output files. The way of writing the output key-value pairs to output files by RecordWriter is determined by the OutputFormat.
OutputFormat instances provided by the Hadoop are used to write files in HDFS or on the local disk. The final output of reducer is written on HDFS by OutputFormat instances.