
MapReduce Fault Tolerance
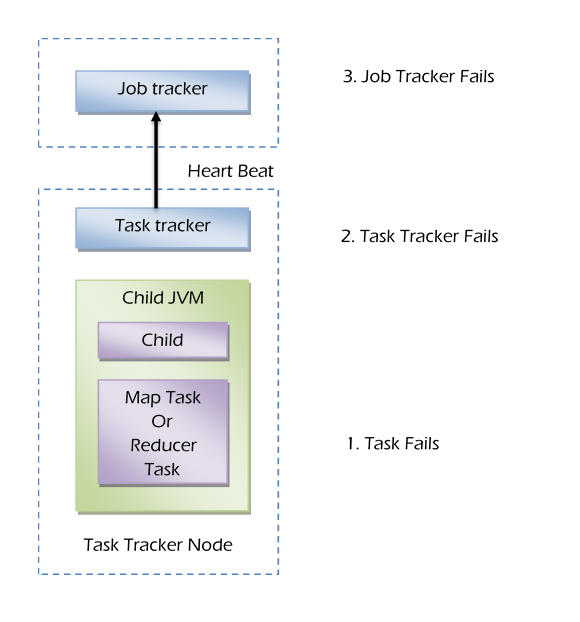
There are mostly three places where the failures can happen. Those are -
- Task Failure.
- Task Tracker Failure.
- Job Tracker Failure.
Task Failure -
If child task fails, the child JVM reports task tracker before it exists. The attempt is to be freeing up slot for another task. If the child task hangs, then it get killed.
Job tracker reschedules the task on another machine. If the continuous to fail, job will be failed.
Task Tracker failure -
When a task tracker is working, the job tracker always used to receive the heartbeat from task tracker. If the job tracker doesn’t receive any heartbeat, then the job tracker assumes that the task tracker has failed.
Job tracker removes the task tracker from pool of trackers to schedule task on. If job tracker does not receive heart beat report from anyone of the task tracker, it considers the task tracker is down and job tracker assign the same task to some other idle replicated node.
Job tracker failure -
This is a single point of failure. If job tracker fails, the entire job will be failed. If any flow in the logic written in both mapper & reducer, there is a chance of getting corrupted/bad records and task will fail because of those records.
In the failure case, job tracker will execute the failed records 4 times by default. In the 4 attempts, if the same job fails all the times then job tracker will mark the entire job as failed.