
MapReduce Shuffle and Sort
After the Map task is completed, the intermediate output is fed to the partitioner. The partitioner class decides which particular Key value pair would go to which reducer. Once the Partitioner completes, shuffling task occurs internally in the cluster.
The output of the partitioner is Shuffled to the reduce node. Shuffling is the process of moving the intermediate data provided by the partitioner to the reducer node. The shuffling process starts right away as the first mapper has completed its task.
Once the data is shuffled to the reducer node the intermediate output is sorted based on key before sending it to reduce task. The algorithm used for sorting at reducer node is Merge sort. The sorted output is provided as a input to the reducer phase.
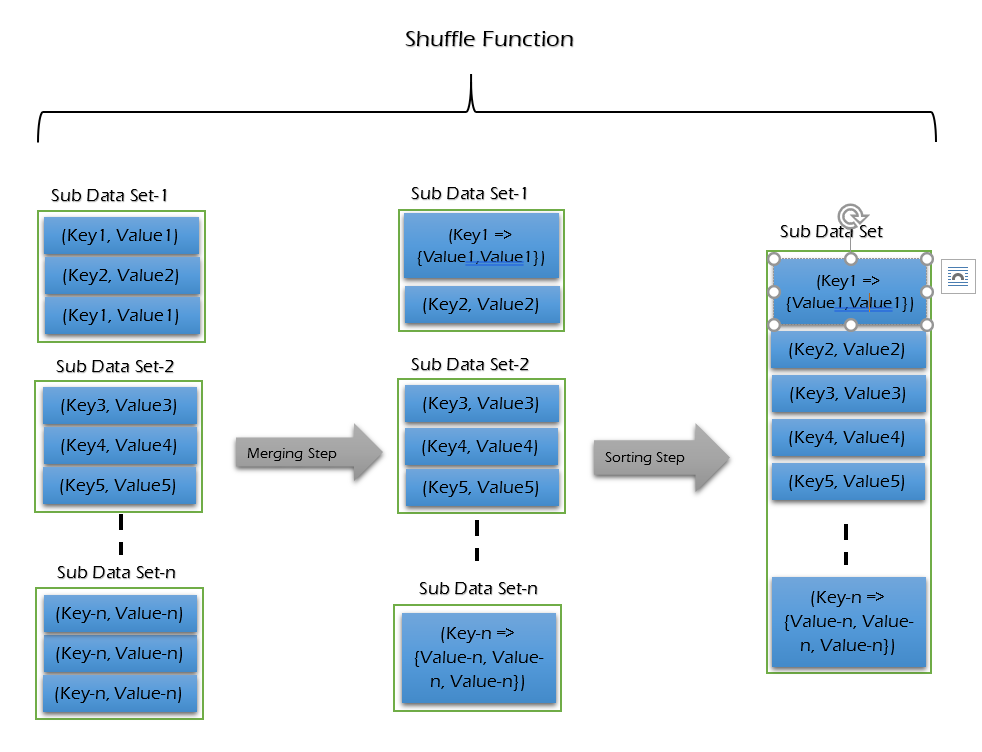
Shuffle Function is also known as “Combine Function”. Mapper output will be taken as input to sort & shuffle. The shuffling is the grouping of the data from various nodes based on the key.
This is a logical phase. Sort is used to list the shuffled inputs in sorted order. It performs the following two sub-steps -
- Merging - combines all key-value pairs which have same keys and returns <Key, List<Value>>.
- Sorting - takes output from Merging step and sort all key-value pairs by using Keys. This step also returns <Key, List<Value>> output but with sorted key-value pairs.
It takes a list of outputs coming from “Map Function” and perform these two sub-steps on each and every key-value pair. Finally, Shuffle Function returns a list of <Key, List<Value>> sorted pairs to Reducer phase.