
MapReduce Mapper
Mapper processes each input record and generates new key-value pair. Mapper maps input key/value pairs to a set of intermediate key/value pairs. Mapper generated key-value pair is completely different from the input key-value pair.
The mapper output is called as intermediate output. The mapper output is not written to local disk because of it creates unnecessary copies. Mappers output is passed to the combiner for further process.
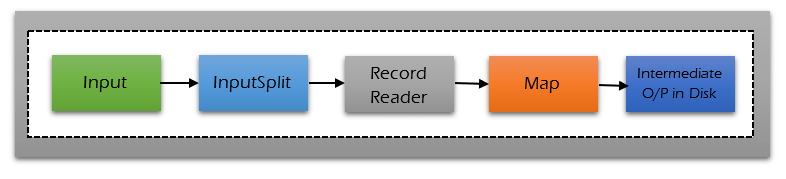
Map takes a set of data and converts it into another set of data, where individual elements are broken down into key pairs. The Mapper reads the data in the form of key/value pairs and outputs zero or more key/value pairs.
The key value pair generated like –
InputSplit -
InputSplit is created by InputFormat. InputSplit logically represents the data to be processed by an individual Mapper. One map task is created to process one InputSplit.
The number of map tasks normally equals to the number of InputSplits. The InputSplit is divided into input records and each record is processed by the specific mapper assigned to process the InputSplit. InputSplit presents a byte-oriented view on the input.
RecordReader -
RecordReader communicates with the InputSplit in Hadoop MapReduce. RecordReader reads <key, value> pairs from an InputSplit. RecordReader converts the byte-oriented view of the input from the InputSplit.
RecordReader provides a record-oriented view of the input data for mapper and reducer tasks processing. RecordReader converts the data into key-value pairs suitable for reading by the mapper. RecordReader communicates with the InputSplit until the file reading is not completed.
Once the file reading completed, these key-value pairs are sent to the mapper for further processing. Mapper is a function to process the input data. The mapper processes the data and creates several small chunks of data. The input to the mapper function is in the form of (key, value) pairs.
Mapper working in MapReduce -
The input data from the users is passed to the Mapper specified by an InputFormat. InputFormat is specified and defines the location of the input data like a file or directory on HDFS. InputFormat determines how to split the input data into input splits. Each Mapper deals with a single InputSplit.
RecordReader used to extract (key, value) records from the input source (split data). The Mapper processes the input is the (key, value) pairs and provides an output as (key, value) pairs. The output from the Mapper is called the intermediate output.
The Mapper may use or ignore the input key. For example, a standard pattern is to read a file one line at a time. The key is the byte offset into the file at which the line starts. The value is the contents of the line itself. If the Mapper writes anything out, the output must be in the form of key/value pairs.
The output from the Mapper (intermediate keys and their value lists) are passed to the Reducer in sorted key order. The Reducer outputs zero or more final key/value pairs and written to HDFS. The Reducer usually emits a single key/value pair for each input key.
If a Mapper appears to be running more slowly or lagging than the others, a new instance of the Mapper will be started on another machine, operating on the same data. The results of the first Mapper to finish will be used. The number of map tasks in a MapReduce program depends on the number of data blocks of the input file.
The InputFormat determines the number of maps -
No. of Mapper= {(total data size)/ (input split size)}
For example, if data size is 500 GB and InputSplit size is 256 MB then,
No. of Mapper= (512*1024)/256 = 2048