
MapReduce Combiners
Combiner acts as a mini reducer in MapReduce framework. This is an optional class provided in MapReduce driver class. Combiner process the output of map tasks and sends it to the Reducer. For every mapper, there will be one Combiner.
Combiners are treated as local reducers. Hadoop does not provide any guarantee on combiner’s execution. Hadoop may not call combiner function if it is not required. Hadoop may call one or many times for a particular map output based on the requirement.
Uses -
- Minimizes the time taken for the data transfer between the map and reduce.
- To limit the volume of data transfer between the map and reduce. In other words, Combiner used to reduce the amount of data transfer over the network.
Example: - Word count example with combiner
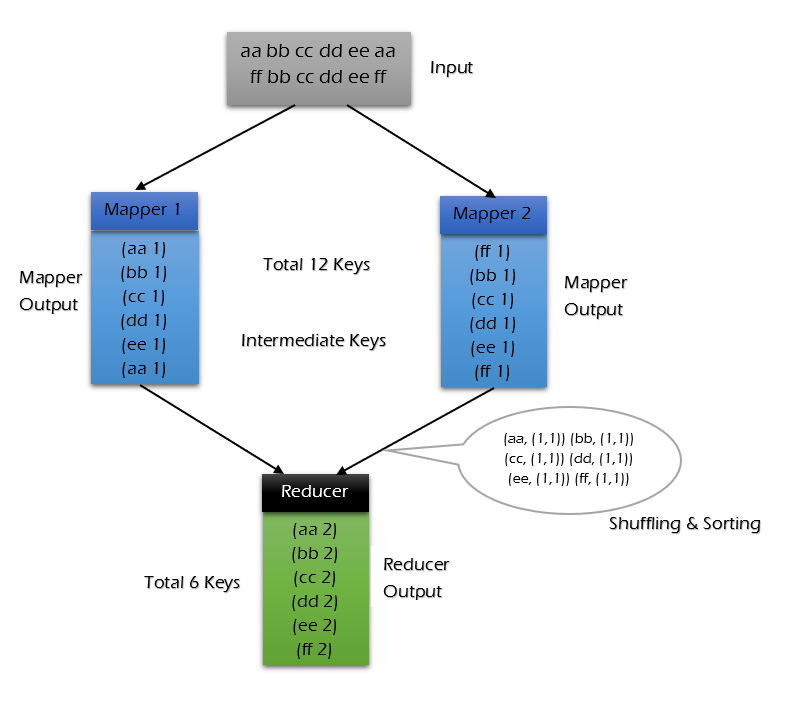
Input - aa bb cc dd ee aa ff bb cc dd ee ff
Let us discuss how the input processed without combiner. Below diagram shows how the mapper and reducer process the input and provide the output.
There are total 12 keys in the input file. The input got processed through a mapper and the same 12 key pairs sends as an input to the reducer.
The reducer provides the output -
Let us discuss how the input getting processed using an combiner in between the mapper and reducer.
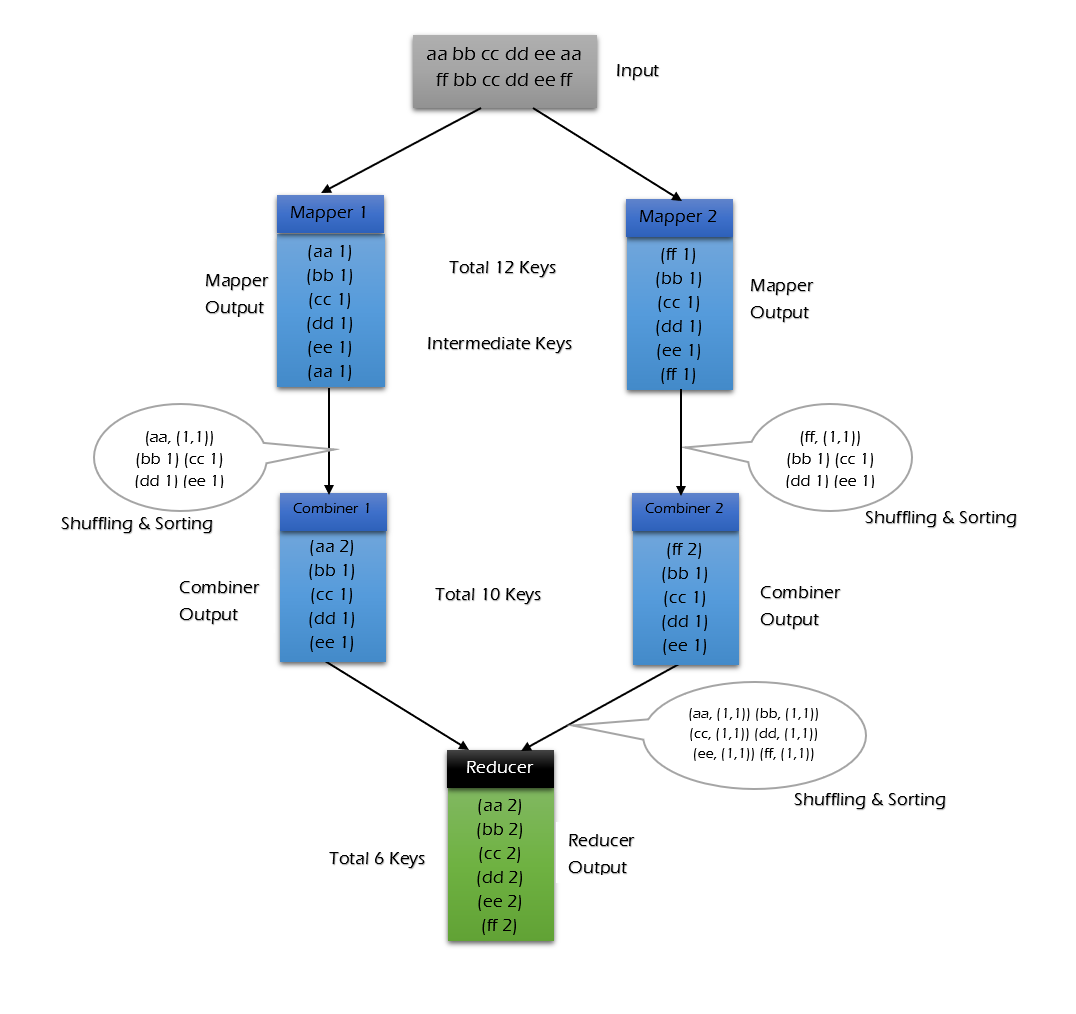
In the above case also, the input got splitted as two parts and submitted to two mappers. The Mappers processed the data and sends it to further processing. The mappers generates total of 24 key combinations.
Before sending the 24 combinations as an input to Reducer, Combiner shuffles the mapper output and then sorts it to reduce the data key combinations. Once the data reduced, the output of combiner submits to the Reducer. Reducer will combiners the inputs from all combiners and provides the final output.
Example: - Word count example with combiner
Input - aa bb cc dd ee aa ff bb cc dd ee ff
Save the input as input.txt and place it in the Hadoop library.
$vim input.txt
aa bb cc dd ee aa ff bb cc dd ee ff
$hadoop fs -mkdir -p /user/user-name/wc/input
$hadoop fs -put input.txt /user/user-name/wc/input/
Program -
package org.example.wordcount;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.
lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce
.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce
.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce
.lib.output.TextOutputFormat;
import org.apache.hadoop.util
.GenericOptionsParser;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class WordcountExample {
public int run(String[] args) throws Exception {
if (args.length != 2) {
System.out.println("Usage: [input] [output]");
System.exit(-1);
}
Job jobex = jobex.getInstance(getConf());
jobex.setJobName("wordcount");
jobex.setJarByClass(WordcountDriver.class);
jobex.setOutputKeyClass(Text.class);
jobex.setOutputValueClass(IntWritable.class);
jobex.setMapperClass(WordcountExampleMapper.class);
jobex.setCombinerClass(WordcountExampleReducer.class);
jobex.setReducerClass(WordcountExampleReducer.class);
jobex.setInputFormatClass(TextInputFormat.class);
jobex.setOutputFormatClass(TextOutputFormat.class);
Path inputFilePath = new Path(args[0]);
Path outputFilePath = new Path(args[1]);
/* This line is to accept the input recursively */
FileInputFormat.setInputDirRecursive(job, true);
FileInputFormat.addInputPath(job, inputFilePath);
FileOutputFormat.setOutputPath(job, outputFilePath);
/* Delete output filepath if already exists */
FileSystem fs = FileSystem.newInstance(getConf());
if (fs.exists(outputFilePath)) {
fs.delete(outputFilePath, true);
}
return jobex.waitForCompletion(true) ? 0: 1;
}
}
public class WordcountExampleMapper extends
Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
StringTokenizer tokenizer = new StringTokenizer(line);
while (tokenizer.hasMoreTokens()) {
word.set(tokenizer.nextToken());
context.write(word, one);
}
}
}
public class WordcountExampleReducer extends
Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable totalWordCount = new IntWritable();
public void reduce(final Text key, final Iterable<IntWritable>
values,final Context context) throws IOException,
InterruptedException {
int totalcount = 0;
Iterator<IntWritable> iterator = values.iterator();
while (iterator.hasNext()) {
totalcount += iterator.next().get();
}
totalWordCount.set(totalcount);
context.write(key, totalWordCount);
}
}
Result -
aa 2 bb 2 cc 2 dd 2 ee 2 ff 2